
MTTFd vs. MTTF vs. MTBF
Why Reliability Metrics Alone Do Not Prove Safety
RISK MANAGEMENTTHE LEARNING LOOP
Manfred Maiers
3/20/20266 min read


MTTFd vs. MTTF vs. MTBF: Why Reliability Metrics Alone Do Not Prove Safety
A component can be highly reliable and still be unsafe. That is the trap many teams fall into when reliability engineering language gets carried into safety decisions without enough rigor. In safety-critical devices, the real question is not simply how often something fails. The real question is whether the failure can create a hazardous situation, whether that hazardous condition is detected, and whether harm can follow. ISO 14971 is built around that broader logic for medical devices, while ISO 13849 and IEC 62061 go deeper into dangerous failure behavior for safety-related control functions.
The three metrics are not interchangeable
MTTF, Mean Time To Failure, is a reliability metric typically used for non-repairable items. It expresses the expected operating time until a failure occurs. In its simplest form, under a constant failure-rate assumption, it is treated as the inverse of the failure rate. It says nothing by itself about whether the failure is benign, merely inconvenient, or hazardous.
MTBF, Mean Time Between Failures, is used for repairable systems. It describes the average time between one failure event and the next during a repair-and-return-to-service cycle. It is valuable for maintenance planning, uptime, and service logistics, but it still does not distinguish between harmless failures and dangerous ones. A system can have an attractive MTBF and still fail in a way that creates unacceptable patient risk.
MTTFd, Mean Time To Dangerous Failure, is different. It is a functional safety metric focused only on failures that can lead to loss of the safety function or otherwise create dangerous conditions. ISO 13849 explicitly uses MTTFd as one of the core parameters for determining the achieved Performance Level of a safety-related control system. IEC 62061, similarly, is concerned with dangerous random hardware failure behavior through PFHd and SIL allocation.
Reliability is about failure occurrence. Safety is about hazardous consequence.
This distinction matters because not every failure matters equally from a risk standpoint. A display backlight failure on a device may create downtime. A pressure sensor drift in a drug-delivery system may create overdose potential. Both are failures. Only one may be dangerous. Functional safety frameworks therefore separate failure modes into categories such as safe failures, dangerous detected failures, and dangerous undetected failures. The undetected dangerous failures are usually the ones that keep safety engineers awake at night.
That is where diagnostic coverage becomes critical. ISO 13849 uses diagnostic coverage as a measure of how effectively dangerous failures are detected. Industry references aligned to ISO 13849 classify DC into bands, and the standard framework combines architecture, MTTFd, diagnostic coverage, and common-cause failure measures to determine the achieved Performance Level. In other words, MTTFd alone is never the whole story.
Why MTBF is often misused in MedTech discussions
In MedTech organizations, MTBF is sometimes presented as though it were evidence that a device is safe. It is not. MTBF can support dependability arguments, spare-part planning, warranty projections, and service expectations. But ISO 14971 does not ask manufacturers to prove safety by quoting a single reliability average. It requires a risk management process that identifies hazards, estimates and evaluates risk, implements controls, and monitors effectiveness across the product life cycle. That is a fundamentally different model.
ISO 14971 also does not equate probability of harm with component failure rate. Between a component failure and patient harm sits a chain of events: operating context, fault propagation, detectability, user interaction, severity of resulting harm, and effectiveness of risk controls. That is why a raw MTTF or MTBF value can never, on its own, establish acceptable residual risk for a medical device.
How the standards use these concepts differently
ISO 14971:2019
ISO 14971:2019 is the overarching medical device risk management standard. It requires a comprehensive process for identifying hazards, estimating and evaluating associated risks, controlling those risks, and monitoring controls over the full life cycle. It was last reviewed and confirmed in 2025 and remains current. The standard is risk-process centric, not metric centric. It does not prescribe MTBF, MTTF, or MTTFd as the primary method for proving safety.
ISO 13849
ISO 13849 is a machinery functional safety standard for safety-related parts of control systems. It uses Performance Levels, PL a through PL e, and ties the achieved level to parameters that include MTTFd, diagnostic coverage, and architecture. The 2023 edition is the current ISO edition, and the standard explicitly treats Performance Level as a way to specify the ability of safety-related control parts to perform a safety function under foreseeable conditions.
A practical feature of ISO 13849 is that it bins MTTFd into ranges. Widely used references aligned to the standard show the typical classifications as: Low: 3 to <10 years, Medium: 10 to <30 years, High: 30 to 100 years. That structure reinforces the point that dangerous-failure behavior, not general failure behavior, is what matters in safety-function evaluation.
IEC 62061
IEC 62061 addresses functional safety of machinery safety-related control systems and uses Safety Integrity Levels, SIL, rather than PL. For random hardware dangerous failures, the standard expresses requirements in terms of PFHd, probability of dangerous failure per hour. Commonly cited ranges for machinery applications are SIL 1: ≥10^-6 to <10^-5, SIL 2: ≥10^-7 to <10^-6, and SIL 3: ≥10^-8 to <10^-7 dangerous failures per hour. The framework is explicitly tied to dangerous failure performance of the safety-related control function.
Comparison table
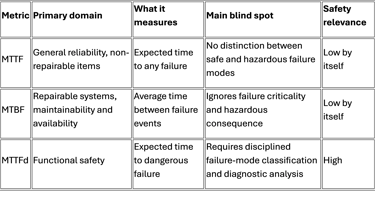
The practical lesson is simple: MTTF and MTBF describe dependability, while MTTFd supports safety-function evaluation. That is why teams working at the boundary of MedTech and functional safety must be careful not to import machinery metrics into medical risk files without context.
A MedTech case example makes the difference obvious
Consider an infusion pump, a complex electromechanical system with sensors, software, alarms, drive components, occlusion logic, and user interface elements. Suppose the pump has an excellent overall MTBF. That may tell you the product rarely goes out of service. But if a flow-sensing chain drifts and the failure is not detected, the dangerous consequence could be over-infusion. From a safety perspective, what matters is not that the pump usually stays operational. What matters is the rate of dangerous failure, the diagnostic effectiveness, the alarm response, and the probability that the sequence reaches patient harm.
Now compare that with a disposable infusion set. It is largely passive. There is no complex repair cycle, no embedded diagnostics, and no software-driven safety function in the same sense. Leakage, disconnection, or occlusion still matter greatly, but the analysis is less about MTBF and more about failure modes, use conditions, process controls, material integrity, complaint trends, and harm scenarios under ISO 14971 logic. The risk model is different because the device architecture is different.
What does this mean for engineering teams
For design and process teams, the rule should be:
Use MTTF when characterizing the general reliability of non-repairable components.
Use MTBF when discussing maintainability and uptime behavior of repairable systems.
Use MTTFd when the question is whether a component or subsystem can fail in a dangerous way that compromises a safety function.
But never stop there. Those metrics need to be integrated with hazard analysis, DFMEA, PFMEA, fault response logic, diagnostic coverage, complaint handling, CAPA signals, and post-market evidence. A component with a long MTTF can still drive intolerable risk if its dangerous failure mode is severe and weakly detectable.
This is also why risk files and FMEAs should not treat all failures as equal. In practice, teams need to distinguish:
Any failure.
Loss-of-function failure.
Dangerous detected failure.
Dangerous undetected failure.
Hazardous situation.
Harm.
Those are not synonyms. Mixing them creates analytical noise, and analytical noise becomes weak risk control decisions.
The strategic takeaway
Many organizations still confuse reliability performance with safety performance. That confusion is manageable in commodity products. In MedTech, it is risky. A reliable device can still expose a patient to harm if the wrong failure occurs, at the wrong time, without detection, under the wrong use conditions. ISO 14971 captures that systems view. ISO 13849 and IEC 62061 reinforce it by focusing directly on dangerous failure behavior of safety functions.
The right engineering mindset is this: risk is not about how often things fail. Risk is about how failures propagate into hazardous situations and whether your controls actually interrupt that path. That is the point where reliability engineering becomes real safety engineering.
Closing thought
MTTF and MTBF are reliability metrics. MTTFd is a safety metric. Treating them as interchangeable can distort design decisions, validation strategy, and even post-market interpretation. You do not manage medical device risk by counting failures alone. You manage it by understanding which failures are dangerous, how they are detected, and how effectively the system prevents harm.